
APACHE-HADOOP-DEVELOPER Online Practice Questions and Answers
Questions 4
Examine the following Hive statements:
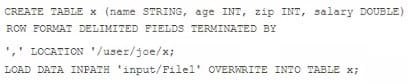
Assuming the statements above execute successfully, which one of the following statements is true?
A. Hive reformats File1 into a structure that Hive can access and moves into to/user/joe/x/
B. The file named File1 is moved to to/user/joe/x/
C. The contents of File1 are parsed as comma-delimited rows and loaded into /user/joe/x/
D. The contents of File1 are parsed as comma-delimited rows and stored in a database
Questions 5
Which one of the following statements describes a Pig bag. tuple, and map, respectively?
A. Unordered collection of maps, ordered collection of tuples, ordered set of key/value pairs
B. Unordered collection of tuples, ordered set of fields, set of key value pairs
C. Ordered set of fields, ordered collection of tuples, ordered collection of maps
D. Ordered collection of maps, ordered collection of bags, and unordered set of key/value pairs
Questions 6
All keys used for intermediate output from mappers must:
A. Implement a splittable compression algorithm.
B. Be a subclass of FileInputFormat.
C. Implement WritableComparable.
D. Override isSplitable.
E. Implement a comparator for speedy sorting.
Questions 7
What data does a Reducer reduce method process?
A. All the data in a single input file.
B. All data produced by a single mapper.
C. All data for a given key, regardless of which mapper(s) produced it.
D. All data for a given value, regardless of which mapper(s) produced it.
Questions 8
Your cluster's HDFS block size in 64MB. You have directory containing 100 plain text files, each of which
is 100MB in size. The InputFormat for your job is TextInputFormat.
Determine how many Mappers will run?
A. 64
B. 100
C. 200
D. 640
Questions 9
You use the hadoop fs –put command to write a 300 MB file using and HDFS block size of 64 MB. Just after this command has finished writing 200 MB of this file, what would another user see when trying to access this life?
A. They would see Hadoop throw an ConcurrentFileAccessException when they try to access this file.
B. They would see the current state of the file, up to the last bit written by the command.
C. They would see the current of the file through the last completed block.
D. They would see no content until the whole file written and closed.
Questions 10
In a MapReduce job, the reducer receives all values associated with same key. Which statement best describes the ordering of these values?
A. The values are in sorted order.
B. The values are arbitrarily ordered, and the ordering may vary from run to run of the same MapReduce job.
C. The values are arbitrary ordered, but multiple runs of the same MapReduce job will always have the same ordering.
D. Since the values come from mapper outputs, the reducers will receive contiguous sections of sorted values.
Questions 11
Which one of the following statements is true about a Hive-managed table?
A. Records can only be added to the table using the Hive INSERT command.
B. When the table is dropped, the underlying folder in HDFS is deleted.
C. Hive dynamically defines the schema of the table based on the FROM clause of a SELECT query.
D. Hive dynamically defines the schema of the table based on the format of the underlying data.
Questions 12
Which one of the following statements describes a Hive user-defined aggregate function?
A. Operates on multiple input rows and creates a single row as output
B. Operates on a single input row and produces a single row as output
C. Operates on a single input row and produces a table as output
D. Operates on multiple input rows and produces a table as output
Questions 13
When is the earliest point at which the reduce method of a given Reducer can be called?
A. As soon as at least one mapper has finished processing its input split.
B. As soon as a mapper has emitted at least one record.
C. Not until all mappers have finished processing all records.
D. It depends on the InputFormat used for the job.
![]()
![]()
Home | About Us | Contact Us | FAQ | Guarantee Policy | Terms & Conditions | Privacy Policy
Any charges made through this site will appear as Global Simulators Limited. All trademarks are the property of their respective owners.
Copyright © 2004-2024 pass2lead.com, All Rights Reserved.